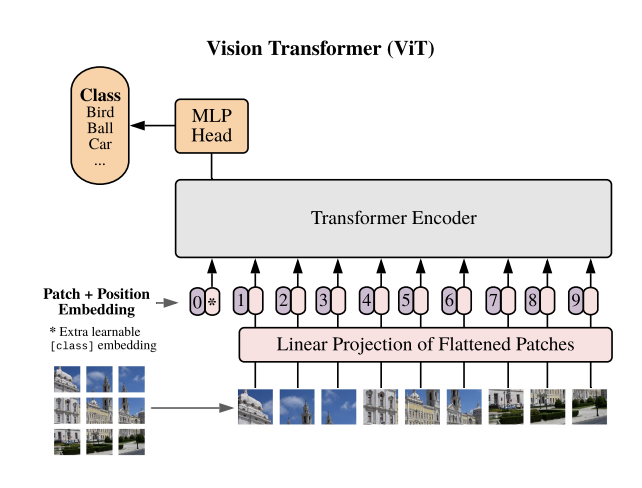
vision transformer 에 대한 글입니다 Vision transformer background https://spicy00.tistory.com/34 https://spicy00.tistory.com/35 그렇다면 어떻게 이 모델을 구현하면 좋을까요? 언어모델에서의 Transformer model 구현은 인터넷에 많은 참고자료들이 있습니다 이와 크게 다르지 않은 모델인데 vision transformer는 transformer의 encoder를 모델로 가져다 사용하게 됩니다. 기존의 transformer encoder와 다른 점은 이것인데요 1. patch 전처리 2. initial linear layer 순서대로 1,2를 지나 multihead attention... 순으로 진행되게 됩니다...